索引下推
索引下推(Index Condition Pushdown)是数据库查询优化的一种技术,它可以在索引扫描阶段就完成一些过滤操作,从而减少需要访问的数据量,提高查询效率。
基本原理
当数据库查询包含过滤条件(如 WHERE 子句)时,传统的做法是从存储引擎读取全部数据,然后在数据库服务器层面进行过滤。 而索引下推则会将这些过滤条件尽量推到存储引擎层,由存储引擎在数据检索阶段直接过滤掉不符合条件的记录。
- 在索引扫描阶段就利用这些额外的列信息来过滤数据
- 减少需要回表(访问主表)的次数
例子
SELECT * FROM users WHERE name LIKE 'Zhang%' AND age > 30;
-- 在name列上创建了一个索引
没有使用索引下推的过程:
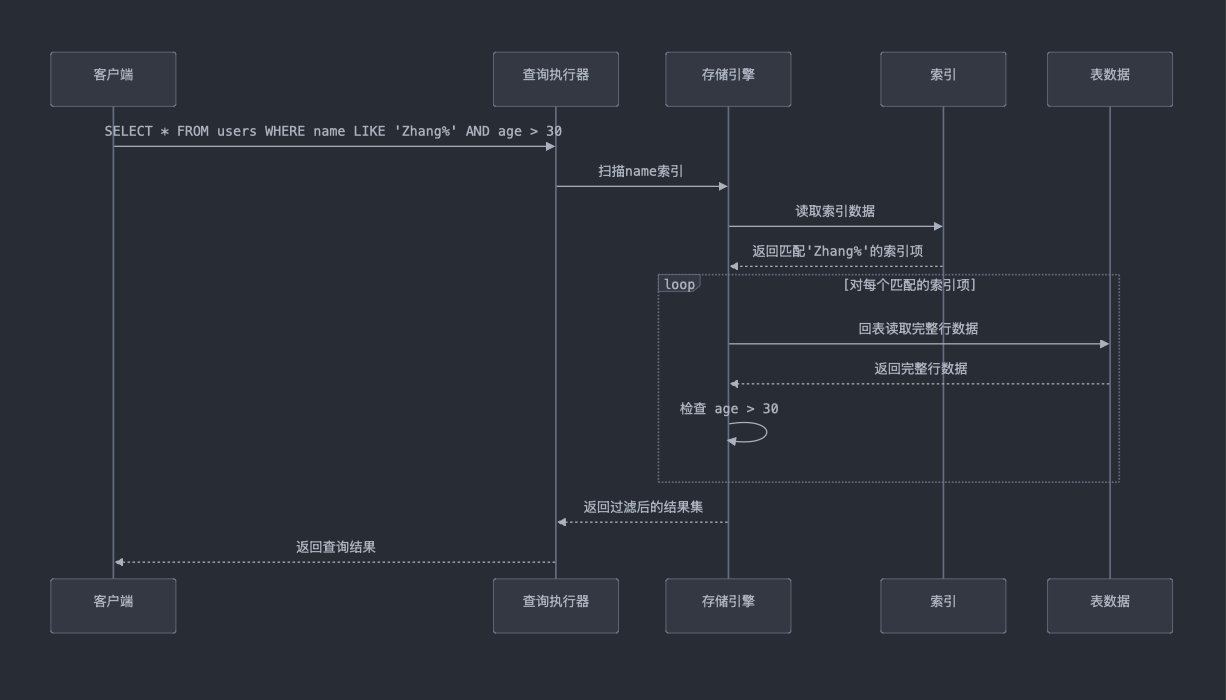
- 步骤1:索引扫描:数据库会利用 name 列上的索引,找到所有匹配前缀 'Zhang%' 的记录。在这一阶段,索引会定位到所有符合 name LIKE 'Zhang%' 的记录。
- 步骤2:回表操作:找到匹配 name 前缀的记录之后,数据库需要进行回表(通过索引找到对应的行,再去表中取完整的数据),并获取每条记录的 age 列数据。
- 步骤3:过滤:在服务器层对每条记录进行过滤,将 age > 30 的条件应用于查询结果。这意味着数据库会把所有匹配 name LIKE 'Zhang%' 的记录都读入内存,然后在内存中执行 age > 30 的过滤。
- 缺点:由于没有索引下推,所有匹配 name 条件的记录都需要进行回表操作,即便它们的 age 不符合条件也会被加载,这增加了I/O操作和内存消耗。
使用索引下推的过程:
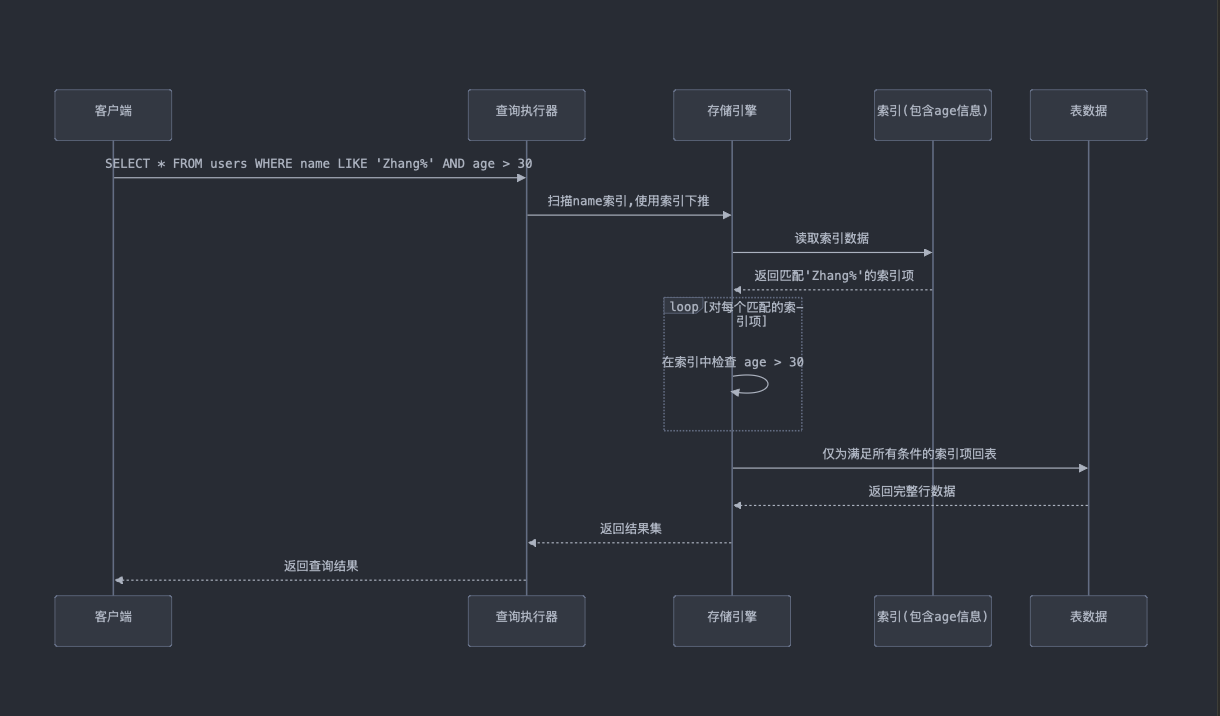
- 步骤1:索引扫描:同样,数据库首先会利用 name 列上的索引,找到所有匹配 name LIKE 'Zhang%' 的记录。
- 步骤2:索引下推:在存储引擎层面,数据库在扫描索引记录时直接应用 age > 30 的条件。也就是说,在索引扫描的过程中,只有那些 age 大于 30 的记录才会进一步处理。这减少了回表操作的次数,因为只有符合 name LIKE 'Zhang%' 且 age > 30 的记录会被回表并提取完整数据。
- 步骤3:回表操作:只有满足两个条件的记录(name LIKE 'Zhang%' 和 age > 30)才会触发回表操作,这减少了 I/O 开销和内存使用。
- 优势:索引下推通过将 age > 30 条件提前到索引扫描阶段,使得在扫描时就可以过滤掉不必要的记录,从而减少了不必要的回表操作,显著提高了查询效率。
索引下推的优势
- 减少数据传输量:因为过滤条件在存储引擎就已经应用,减少了服务器端需要处理的记录数。
- 提高查询效率:尤其是对于复杂的查询条件,索引下推能显著减少数据扫描量,提高查询的响应速度。